Contents
- Introduction
- My story
- The machinery
- The signal
- The data
- The process
- Other matters one
- Other matters two
- Conclusions
Introduction
The paper at reference 1 appears to be homing in on an area well inside the brain, the anterior insular cortex, as being key to consciousness, this last being something in which I have taken an interest. Turn this area off and while plenty of stuff might be going on in the brain, it won’t make it upstream to consciousness. But some way into the paper, which is built on a sophisticated analysis of fMRI images, I decided that I did not know enough about fMRI – functional magnetic resonance imaging – technology which has been around for around twenty years now – to understand what was being suggested. So I embarked on a spot of Bing-enabled teach yourself.
For once, I did not find the Wikipedia article (reference 2) particularly helpful: it wasn’t pitched at the right place for me. But then I got to references 3 (9 pages) and 4 (27 pages), both a little long in the tooth now, but open access and both helpful. And being long in the tooth was hopefully not a problem for me; hopefully the basics that I wanted to get a grip on are not changing that fast. After all, the underlying physics is not changing. So the short story followed of reference 4 followed by the long story of reference 5. But first, what is it all for?
 |
| Figure 1 |
While fMRI with the ‘functional’ might be mostly about brains, MRI more generally can be used to image any part of a body, human or otherwise, as in the figure above, an image of a knee and the anterior cruciate ligament (ACL), apt to be unpleasantly damaged by high performance athletes.
While the functional bit might be taken here as being about taking pictures of a brain at work, rather than as a static structure – and fMRI can do just that: it can show us what bits of the brain are involved in what sort of brain work. And it can do that with a live person in a reasonably non-intrusive way. At least it doesn’t (usually) involve drinking beakers of odd tasting fluids, sticking anything in or opening the head up – although I did come across some concerns about transient side effects of the very large electrical and magnetic fields involved.
 |
| Figure 2 |
The image above shows regions of the brain activated during a sentence completion task from the library of science photos at reference 18, turned up for me by Bing. Very much the sort of thing that crops up all the time in computational neuroscience.
 |
| Figure 3 |
While this third image is a rather more heavily processed set of images, the sort of thing that cropped up towards the end of reference 16. But is actually one of the supplementary figures at reference 1, my starting point.
My story
MRI and fMRI is a big scientific and medical success story. It is used all over and it is either the subject or the vehicle of what must be a huge number of scientific papers. I dare say both the machines and the work they are put to are coming on by leaps and bounds. But as I read somewhere in the course of all this, in trying to write explanatory material, it is hard to strike the right balance between being elementary and being far too deep for the non-specialist. It is a complicated jigsaw as well as being a moving target and it is hard to make it into popular science. References 3 and 4 notwithstanding, I did not find a story which really satisfied me, which was pitched at the right level for me.
With the result that the whole business has soaked up a good deal of time as I brushed up on my sketchy knowledge of all the science, statistics and mathematics which has gone into MRI and fMRI. As I attempted to work my way through a digestible portion of the huge amount of tutorial material available on the Internet, for some of which you are invited to pay. See, for example, reference 8. For which you are not invited to pay.
At the end of all this, mainly to test my own understanding, I have attempted my own summary, which now follows. A summary of what seems important to me, another short story. Not very sure what the target audience might be, but I do associate to FIL, who on reading a pamphlet I had given him about organising for mental health, an industry of which he was very much part at the time, remarked that it was a fine summary for those who already knew. And I dare say that traditional civil service minutes of my day about things that were complicated, by way of cunning compression of a lot of tricky detail into a very small number of words, sometimes fell into something of the same trap. But nonetheless, something to aim for.
 |
| Figure 4 |
Lifted from reference 3.
 |
| Figure 5 |
Maybe the first point to make is that both brains and fMRI data contain a great deal of noise, illustrated first by a simple graphic from reference 3, second by a more complicated graphic from reference 4. With the latter showing how much noise is left after fitting the model (black line) to the signal (grey line). In which circumstances, one clearly needs to have a care not to erect elaborate castles in the air, to erect castles on feeble foundations. Serious statistical input is essential – with reference 4 being something by way of a job creation scheme for statisticians.
The machinery
 |
| Figure 6 |
Scanners are room-filling pieces of machinery on which you might make a capital spend of the order of £500,000. Then there are the running costs.
Scanners use a lot of energy, perhaps 25KWH for a head scan, with consumption peaking at 75KW. Over time, supercooling the magnets accounts for getting on for half the total, I think additional to the figures just given. Reference 6 suggests that energy planning is not taken as seriously as it might be.
Machinery which one might think was potentially dangerous to the subject given the huge magnetic fields being generated, but the people concerned appear to have satisfied themselves that exposing a brain to these sorts of fields is safe, be they resonating ever so fast. Machinery which one might think was potentially dangerous in a more general, H&S sort of way, given the huge magnetic fields being generated, given the use of liquid helium to cool the magnets and the amount of electricity needed. Do they ever catch fire?
There are five main components. The biggest, outer ring is the magnets generating the huge static field, measured in something called Teslas (for a Serbian-American engineer), perhaps as many as 10 of them, running through the middle of the white doughnut in what is called the z direction. Then something called the shims which smooth out that generated field. Then a middle ring for the three sets of coils – one set for each of the usual x, y and z directions – generating the rather smaller gradient fields – fields which change very fast during a scan – gradients which provide the spatial information needed to build an image. Then an inner ring for the coils transmitting and receiving radio frequency (RF) bursts of energy, otherwise the transceiver. And, fifth and last, the computers and software needed to drive all this.
The resonance in question is the oscillation of the magnetic fields generated by disturbing the spin state of polarised protons and neutrons in the nuclei of atoms of living tissue, for these purposes nearly always the protons in the hydrogen atoms in the head of the subject. You also get a lot of them in water. The frequency of these oscillations is a function of the element – hydrogen in this case – and the size of the external magnetic field; perhaps 50 or 100MHz in VHF radio-speak. It might also be thought of the frequency of rotation, of the spin of the nuclei in question. While the N for nuclear got dropped from NMRI as it put people off.
So, in short, you put a pulse of RF energy from the transceiver into the sample, disturbing the spins away from their equilibrium values. These disturbed spins then relax back to the low energy equilibrium state, giving out RF energy, putting energy back into the transceiver, as they go.
This relaxation might take place in tens of milliseconds, or hundreds, depending how you look at it. And the speed of relaxation depends, inter alia, on the tissue in question. Part of this is the amount of oxygen in the blood, a popular proxy for neural activity, from which we get BOLD for blood oxygen level dependent, an acronym which crops up everywhere. A popular proxy despite the fact that the blood oxygen response is rather blurred in both space and time, making resolution below millimetres and seconds difficult.
 |
| Figure 7 |
Discussion is often framed in terms of T1 relaxation, T2 relaxation and T2* relaxation. The snap above, taken from reference 3b, gives some idea of the (millisecond) values of the first two of these for a range of field strengths then available. With the headline being that T1 relaxation is a lot slower than T2 relaxation, which makes it possible to focus on one rather than the other.
It is the big static field which polarises these protons in the first place; the RF pulses which excite those protons from that equilibrium polarisation; and, the gradient fields which translate position inside the scanner to the frequency of the decay resonance of the excited protons. Note that the frequency of the decaying signal is a function of the field at the time the signal is sampled, not the field at the time that the protons were excited in the first place. With the former field changing very rapidly during that decay.
It is all these very fast changes to the gradient fields which make the (considerable amount of) audible noise which subjects of both fMRI and MRI complain of, particularly when heads are involved.
The signal
The object of all this machinery is a interesting map of signal across the brain. And to be interesting, there has to be contrast, there have to be systematic and significant differences in the signal between one place in the brain and another. The grey scale of the Figure 1 we started with.
 |
| Figure 8 |
The above being a block diagram version of the more usual pulse sequence diagram reproduced below, from Wikipedia. As it happens, for a spin echo type of pulse sequence.
Glossing, we need a big enough sample of the signal in frequency space, often called K-space, in order to be able to map, by means of an inverse Fourier transform, that sample into the regular space we can look at in the ordinary way.
 |
| Figure 9 |
These pulse sequence diagrams are widely used and there are a number of different varieties, but the plan is always much the same: the time course of various activities, five of them in the diagram above. Activities on the vertical y axis and time on the horizontal x axis. The top line is the exciting RF pulses, with the shape of these pulses being that of the sinc function, that is to say sine(x)/x. The middle three lines are the activities of the three gradient magnets: z for through the middle of the doughnut, x and y for the orthogonal plane. In the simple case a value of z corresponds to a slice of the recumbent brain, selected by resonant frequency by the z gradient. The bottom line is the sampling of the RF signal from the decaying resonance.
PE is the phase encoding applied to the y-axis, FE is the frequency encoding applied to the x-axis. Have yet to work out what SS stands for, but the second one is the spin inverting pulse which generates the spin echo, for which see below.
Scanners often come with a portfolio of pulse sequences from their manufacturers. A popular one from Siemens is called FLASH – flash for ‘fast imaging using low angle shot’.
Remembering that the object is to produce an image of the brain every so many seconds (functional) or minutes (structural), an image expressed as a value for every voxel. With the two sorts of image using different contrasts and yielding different resolutions.
This value is sometimes called intensity, otherwise local spin density, and if figures 4 and 5 are anything to go by, is of the order of 10,000.
The data
It is convenient to present the end point at this point, that is to say the images that emerges from the scanning process – which process will be covered in the section following.
 |
| Figure 10 |
So we have an experiment to explore something or other brainy, with the main business being fMRI scans of the brains of a number of subjects, usually while they are doing some set, time delimited, repetitive task; often arranged in blocks. Perhaps 25 or so subjects, perhaps a lot more. Noting that a huge amount of fMRI data is freely available online these days, so sometimes you don’t even have to bother with your own experiment.
A complete scan of a head is called a volume and might take a few seconds to complete. In course of any one experiment any one subject might be scanned 100 times or more over a period of a quarter of an hour or so, the idea being to see what changes as the subject’s activities change – mostly mental rather than physical activities as the subject is inside the scanner for the duration – which some find claustrophobic and there is a panic button. These functional volumes about brain activity will be supplemented by a rather more detailed structural scan of brain anatomy. This takes rather longer. So maybe more than 2,000 volumes in all, for the whole experiment.
Each volume is organised as a number of slices, rather in the way that a lump of bacon used to be fed through a bacon slicer. Each slice is organised as a two dimensional array of voxels, which might be as small as a cubic millimetre.
Remembering that while the discussion here is rather space orientated, we can also think in terms of a time series for each voxel, and we might be as interested in variation in time as in variation in space, in particular in the correlation between the two.
In order to compare one scan with another and one subject with another, scans are mapped onto a reference head, examples of which are to be found at reference 5. A mapping which is disturbed to the extent that one subject’s brain is different from another subject’s. Further disturbance might result from mapping the three dimensions of the reference head onto the two dimensional plane, for ease of visualisation. The sort of thing noticed at reference 16.
Remembering in all this that a voxel contains a lot of neurons, tens of thousands at least and usually a lot more. Mechanical neurons in these sorts of numbers can do a great deal of work, and it reasonable to suppose that real ones can too. We might have a lot of voxels, but they are giving us the macro view, not the micro view.
The registered images from a session with a subject, perhaps an array of real values, that is to say numbers like 26.09 and 484.63, for 100,000 voxels in space by 100 points in time, are quite a good break point. Images which can readily be converted to grey scale images on a computer screen. To the extent that those images work, that they tell us something interesting (and true) about the workings of the brain, we may not interest ourselves in all the science and all the work which generated those images.
The process
 |
| Figure 11 |
Lifted from reference 4.
As noted above, the end product of an fMRI scanning session is usually a large matrix of real valued numbers, perhaps 100 times by 100,000 voxels worth of them, so a lot of data – quite intractable without modern computing machinery. Data analysis is working out whether there is something interesting to say about that data. Has the experiment identified regions (localising brain activity in the figure above) or networks (connectivity in the figure above) in the brain of particular interest?
But quite a lot has to be done to get to that point, starting with capturing the data from the scanner. Getting all that right was a challenge in itself, certainly in the early days. More mature technology now.
Next comes building the image, that is to say one value (of something) for each voxel.
 |
| Figure 12 |
Lifted from reference 4.
Perhaps the place to start is the fact that the resonant frequency, the frequency of the radiation produced by these disturbed nuclei, is proportional to the strength of the ambient magnetic field. In brief, by putting suitable gradients on that magnetic field we can extract information about position from information about frequency collected by the RF transceiver and then convert than information about position into images. One such gradient, the z gradient, runs through the hole in the middle of the doughnut.
Slightly less briefly, the brain is usually nose up in the hole in the middle of the scanner. An often vertical slice across that brain (from ear to ear, as it were) is selected by adjusting the frequency of the exciting RF pulse from the RF transceiver, which has to be near the resonant frequency of the target nuclei to work. The decay of that excitation results in a signal which can be picked up by the RF coils. That signal is a function, inter alia, of the x gradient and the y gradient, otherwise the two dimensional k-space. The signal is then sampled for a sequence of k-space values which span that space. An inverse Fourier transform is applied to yield a sequence of values which span the slice, a value for every voxel, in other words an image of that slice. The scanner then moves onto the next slice and eventually you have a three dimensional image of the brain, including here the interior. All this being another rather glib gloss on a rather complicated story. But it is worth adding that there is a trade off between the number of sample points, that is to say the resolution of the image, and the time taken to produce the image.
Pre-processing
Next comes the pre-processing phase, which can be divided into four components. First, given that each slice is taken a different time, the data is adjusted so that all the slices making up a volume can be given the same time. The volume can then be regarded as an instantaneous snapshot. Second, corrections need to be made for head movement. Perhaps corrections for breathing. After which each low resolution functional scan is mapped onto the high resolution structural scan. And the high resolution structural scan is mapped onto whatever reference brain is being used, the brown box in the box model above. This means, some loss from the mapping process apart, all the functional scans are now coded to the same frame of reference and may be compared. Third, a bit of spatial smoothing is applied, in line with the intuition that activation of one voxel is likely to be influenced by the activation of neighbouring voxels.
Data analysis
We now have a set of functional images, which might be considered as a three dimensional matrix of voxel values: subject (maybe ~25) by time (maybe ~100) by voxel (maybe ~100,000), and which we wish to analyse. Maybe the form in which fMRI data is usually made available to others.
The workhorse of data analysis seems to be general linear modelling (GLM). Glossing, the user provides a ‘prior’ in the form of the time course, perhaps several hundred times, of various experimental variables or conditions, perhaps half a dozen or so of them, say a matrix of N times by M variables, and the model provides a best fit ‘posterior’ in the form of data values, one for each of K voxels, that is to say an image, plus an error for each of those K voxels. Perhaps, by way of an example, an image of regions of the brain which have been deactivated by thinking about fish and chips. With the experiment being, for each subject, a twenty minute random sequence of 20 seconds blocks of thinking about fish and chips, squeezing a small rubber ball in the right hand and rest.
Note that in this example we have lost time. All we get out at the bottom is an image. With Figure 2 being a slice from such an image. But a manufactured image, at some considerable distance from the image from a tissue slide taken through an optical microscope with a Box Brownie.
Data analysis includes the tricky business of deciding when an interesting looking image is significant. That one is not looking at some chance result or some artefact of the complex systems which have been deployed to produce it.
Other matters one
Various topics turned up along the way, most of which a proper statistician (that is to say, not me) might be expected to know about.
Echoes
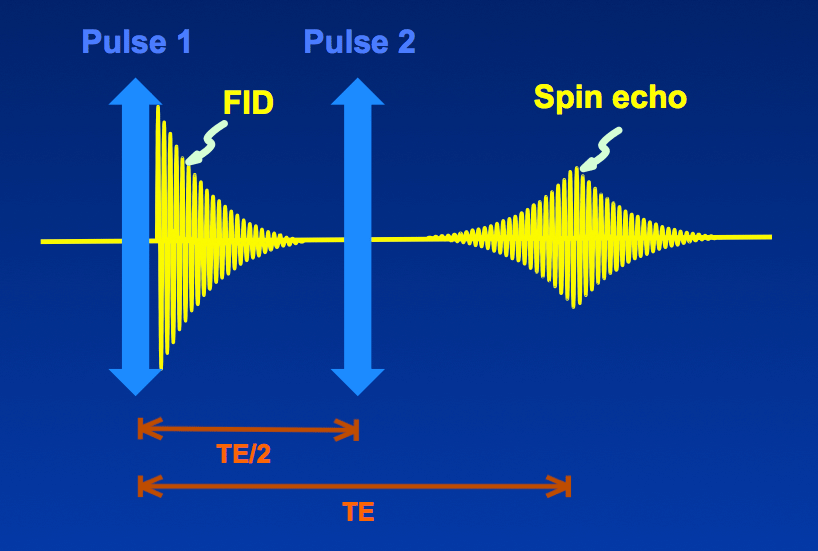 |
| Figure 13 |
The caption to the original of the snap a above reads: ‘A single RF pulse generates a free induction decay (FID), but two successive RF pulses produce a spin echo (SE). The time between the middle of the first RF pulse and the peak of the spin echo is called the echo time (TE)’.
One might use the term ‘echo’ a little loosely to cover the whole of the RF output response (yellow in the example above) to the RF input pulse (blue). But there is also a rather special meaning, derived from the spin echo discovered by Erwin Hahn, more than seventy years ago. I rather struggled with what this was, but eventually I turned up reference 7 which put me on the right track.
Gradient echoes and spin echoes are important in technical treatments of fMRI. They crop up in the methods sections of papers depending on or about fMRI.
Balloon models
One of the alternatives to GLM is one of the balloon models, in which blood flow in cerebral blood vessels is modelled, rather than just summarised in a linear model. Balloon comes from the tendency of some blood vessels to swell and shrink back, rather in the way of an elastic balloon, in the course of the heart’s pumping cycle.
Not linear and admirably general, but with plenty of problems of its own.
Markov random fields and Gaussian random fields
One of the ways to look large arrays of (say) two dimensional statistics is to generalise the idea of a Markov chain – where the probability of the nth member of the chain taking any particular value depends only on the value of the (n-1)th member – to two dimensions. Whereby the probability distribution of the value of a cell in a two dimensional array depends only on the values taken by neighbouring cells.
Much work has been done on this, drawing on prior work in statistical physics and agricultural plot trials. Including something called the Hammersley-Clifford theorem.
Gibbs sampling
It has been shown, that under various assumptions, that if you know the probability of a vector x given a vector y and the probability of that same vector y given the vector x, that it is possible to extract the probability of x. Or, put another way, if you know the conditionals you can get the marginals. Gibbs sampling is an iterative procedure for getting those marginals, by way of a suitably large number of sample points from that marginal distribution.
Random number generators
It seems that one of the workhorses of statistical computing is the random number generator, something that will generate random numbers uniformly distributed between zero and one; the sulphuric acid, as it were, of said statistical computing. I once made quite a lot of use of the ‘Rnd’ function supplied by Microsoft’s Excel and was never able to detect any irregularities. But how can you be sure? Especially if you are using the function on an industrial scale, generating millions of random numbers?
 |
| Figure 14 |
By way of an elementary experiment I gave Excel another go. Which looked well enough.
 |
| Figure 15 |
But not so well when one changes the scale, the one immediately above being that selected by default, by Microsoft. Which serves to remind one that care with presentation is essential.
 |
| Figure 16 |
Despite appearances, things are getting better. Ten times the number of numbers, but the range of the bin counts has stayed at not much more than 1,000.
Other matters two
It seems that reference 9a, a poster for a paper about doing fMRI on a dead salmon, did much to highlight the poor quality of the statistical work going into a lot of real fMRI papers at that time, around ten years ago. The paper itself, reference 9b is not open access so not yet looked at, but it does seem that things have got a lot better since.
Scare stories about sloppy statistics more generally pop up from time to time, not all fuelled by the explosion of work on fMRI. For example references 10-13. While I worry about the amount of statistical knowledge needed to do brain or psychology flavoured research. Worries which surfaced at references 14 and 15.
The good news is the amount of information about almost anything that can be dug up from the Internet. With the fMRI learning resources from Canada at reference 8 being a good example.
Conclusions
It seems that all self respecting teams working with fMRI need to include a statistician with appropriate expertise and experience. Or at the very least have access to one such. And, more tricky, even the lowly reader of reports from these teams needs such knowledge or access.
In which connection, I imagine the increasing availability of well-packaged computer software is something of a mixed blessing. Such software might hide a lot of unpleasant statistics away, out of sight – but out of sight is out of mind – which last might well be the source of much error.
Nevertheless, I now feel I now know enough about fMRI to go back again to my starting point at reference 1.
 |
| Figure 17 |
PS: my copy of the book at reference 3b, started life in the library of St. Thomas’ Hospital, apparently part of Kings College, and was then sold to me in aid of the Rainbow Centre in southwest Sri Lanka. The snap above being taken after a storm there in November, 2017.
References
Reference 1: Anterior insula regulates brain network transitions that gate conscious access - Zirui Huang, Vijay Tarnal, Phillip E. Vlisides, Ellen L. Janke, Amy M. McKinney, Paul Picton, George A. Mashour, Anthony G. Hudetz – 2021.
Reference 2a: https://en.wikipedia.org/wiki/Functional_magnetic_resonance_imaging.
Reference 2b: https://en.wikipedia.org/wiki/Nuclear_magnetic_resonance.
Reference 3a: Overview of fMRI analysis – S M Smith – 2004. 9 pages. Smith is Professor of Biomedical Engineering at the Wellcome Centre for Integrative Neuroimaging at Oxford.
Reference 3b: ‘Functional MRI: an introduction to methods – Jezzard P, Matthews P, Smith S, editors – 2001’ – which appears to be something of a standard text. It includes prior publication of reference 3a.
Reference 4: The Statistical Analysis of fMRI Data - Martin A. Lindquist – 2008. 26 pages. Lindquist is a professor at the Bloomberg School of Public Health, at John Hopkins, at Baltimore, Maryland.
Reference 5: http://nist.mni.mcgill.ca/?s=Stereotaxic+Registration+Model.
Reference 6: The Energy Consumption of Radiology: Energy - and Cost-saving Opportunities for CT and MRI Operation – Tobias Heye, Roland Knoer, Thomas Wehrle, Daniel Mangold, Alessandro Cerminara, Michael Loser, Martin Plumeyer, Markus Degen, Rahel Lüthy, Dominique Brodbeck, Elmar Merkle – 2020.
Reference 7: Atomic memory: atomic systems that have decayed from some ordered states can be induced to recover their initial order. The degree to which order is restored allows investigation of interactions difficult to observe – Richard G. Brewer, Erwin L. Hahn – 1984.
Reference 8a: http://www.fmri4newbies.com/. Part 1. A learning resource from Western University, London, Ontario, for which see reference 13.
Reference 8b: http://www.newbi4fmri.com/. Part 2.
Reference 8c: https://www.uwo.ca/. Western University.
Reference 9a: Neural correlates of interspecies perspective taking in the post-mortem Atlantic salmon: An argument for multiple comparison correction (open access poster) – Bennett, Baird, Miller, Wolford – 2009.
Reference 9b: Neural correlates of interspecies perspective taking in the post-mortem Atlantic Salmon: an argument for multiple comparisons correction (paywalled paper) – C M Bennett, M B Miller, G L Wolford – 2009.
Reference 10: The Salmon of Doubt: Six Months of Methodological Controversy within Social Neuroscience - Daniel S. Margulies – 2011.
Reference 11: P > .05: The incorrect interpretation of “not significant” results is a significant problem – Richard J. Smith – 2020. Paywalled.
Reference 12: Why Most Published Research Findings Are False – John P. A. Ioannidis – 2005.
Reference 13: http://psmv2.blogspot.com/2016/01/voodoo-time.html. One of my own contributions. Mostly about fMRI as it happens.
Reference 14: https://psmv4.blogspot.com/2019/06/hard-for-me-to-know.html.
Reference 15: https://psmv4.blogspot.com/2019/06/more-hard-for-me-to-know.html.
Reference 16: https://psmv4.blogspot.com/2018/11/places-in-brains.html.
Reference 17: https://www.sciencephoto.com/. The source of Figure 2.
Reference 18: http://mriquestions.com/spin-echo1.html. The source of Figure 13.
Reference 19: https://1drv.ms/b/s!AvPvDT7vzzpQhuMXVdkxwlJ75OI30w?e=Tb4Cll. A publicity brochure for what I assume is a modern scanner from Seimens. Not much liquid helium at all. Also an experiment with OneDrive sharing.
No comments:
Post a Comment