I am presently working on a language which is intermediate between a natural language like English and computer languages like Basic (a general purpose programming language) and SQL (a database language). With all three being very widely used. Perhaps a rather uncomfortable compromise, but that is a matter for another day.

This language is made out of characters drawn from a finite set, say 256 of them. The upper and lower case letters, perhaps some letters to accommodate the accents of foreigners, the numerals and a selection of special characters. But little on presentation, none of the stuff snapped above, offered by Microsoft’s Excel. None of the stuff hidden inside Microsoft’s Word used to further control the appearance of text on the page or screen.
The usual idea is that a text is made up of a finite sequence of characters, a sequence of characters which is mapped in a more or less complicated way onto the page of a book or the screen of a computer. Text which can be considered to occupy a finite, two dimensional rectangle, typically a good deal longer than it is wide.
Now, in any particular context, a character has a fixed length. In the early days of computing, all the characters always occupied the same, fixed size rectangle, perhaps twice as high as it was broad, on the screen. With the screen being made up of a fixed, two dimensional array of such rectangles, perhaps 50 lines high by 100 characters across. With printers, at that time not much more than fancy typewriters (and using a similar, if rather larger, printing ribbon), taking a similar position.
Against which background, from time to time, I wonder what one would get if one relaxed that presentational rule.
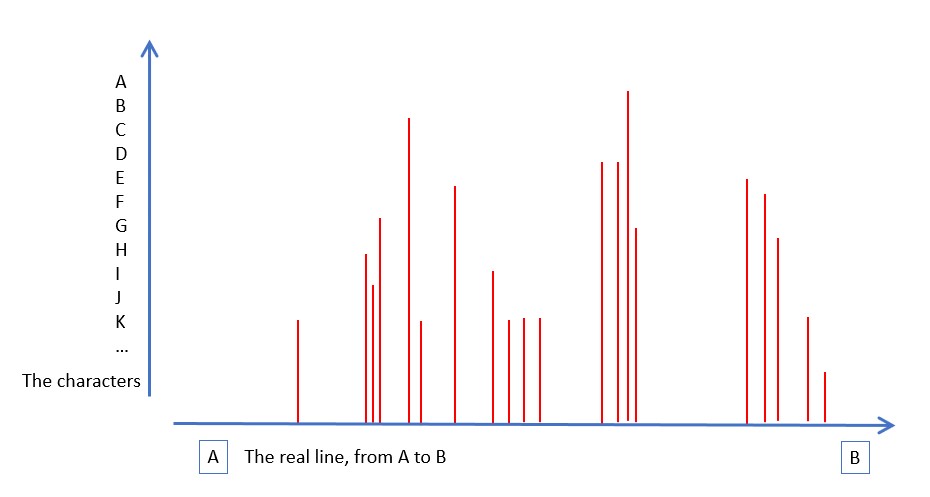
Let us suppose that we have a sequence of N characters mapped onto the segment [A, B] of the real line where A and B are real constants, B > A.
This sequence can be expressed as a function M from the real line to the set of integers [0, 255]. We treat ‘0’ as the null character.

So we have already added something, that is to say position, to the characters of our sequence – with position being rather more than the order we had before. Not nonsense, as one might have such a map if one transcribed spoken speech, with the position of each line corresponding roughly with the time the character in question was uttered. Remembering that there is no natural or exact way of actually doing this, although one can make approximations.
Let us suppose now that we allow N to become arbitrarily large.

Then it can readily be shown that at least some points, the characters become dense. In the jargon of mathematicians, there must be some limit points. Not too many of them or things would get out of hand. The sort of thing one looks at in mathematics classes, as in the snap above, from the people at reference 1, turned up by Google.
So the question for this morning is whether one can ascribe any sensible or interesting meaning to such maps? Is there any point in this particular extension to the normal way of doing things?
Maybe we had ‘Peter thought that Mary thought that David thought that Petunia thought that Frederick said that Marie-Louise believed that …’, otherwise’ Peter thought that (Mary thought that (David thought that (Petunia thought that (Frederick said that (Marie-Louise believed that …))))))))’. Where the nesting just gets deeper and deeper. Or, taking a leaf out of a religious text – and many old texts are into this sort of thing – (David was the son of SUB(Peter was the son of SUB(Frederick was the son of SUB(Isaac was the son of SUB( …))))))))’. Where the reserved word ‘SUB’ means that it is the subject of the subordinate clause which figures in the superior clause, a wheeze rather like the relative pronouns – who, whom and the like – in English. Then we might decide that such more or less infinite nesting ought to be constrained behind a limit point.
Could one go one better and put a metric on our set [0, 255] of integers? A metric which perhaps wrapped these numbers around a circle, ending up at the beginning? Not that alphabets or character sets are in any way like that in the real world; there might be a natural order on the numerals or the upper case letters, but for the character set as a whole, no. Metric no, except in the case of the numerals.
Clearly something to be mulled over when I haven’t got anything better to do.
PS 1: maybe, if one analysed letters into their oral components, mapping all the letters onto some complicated multi-dimensional space, one would find that those letters were evenly distributed along some more or less complicated one-dimensional line in that multi-dimensional space, thus giving us a natural order and a metric. Who knows?
PS 2: if you can’t be bothered to work out the answers to Problem 2.7 above, you can flash the plastic at the people at reference 1 and they will tell you what they are.
References

Reference 1: https://www.chegg.com/. A serious looking, for-profit, online learning operation.
No comments:
Post a Comment